
读 NeRF 论文
读 NeRF 论文
摘要:
之前是只听说过,然后简单了解了机理,没真正读过NeRF。这次来读一下,就是先翻译,然后记下来。肯定有疏漏,或许有不对的地方,不过对我够用了。我把直接翻译出来的用黑体表示, 把和具体实现相关的用斜体表示,我能看懂的拿我理解的话说出来。
NeRF全程叫 Representing Scences as Neural Radiance Fields for View Synthesis。字面意思大概是:对于视角合成问题,将场景描述为神经辐射场。
就是说,发明了一种方法,具体就是说,用一系列稀疏的视图集合,还原出场景的新视图。(注意到这里说的不是还原出整个场景)。
算法使用全连接(特意强调了一下不用卷积)深度神经网络表达一个场景,输入是五维坐标,输出是“the volume density and view-dependent emitted radiance at that spatial location”,在空间位置的体积密度以及依赖于视角的发射的radiance。
如何用我们的刚才说的算法合成这个场景的新视角视图呢:论文中说的是,沿着相机射线查询5D坐标(相机位置3维,相机视角两维),并使用经典的体渲染技术(classic volume rendering techniques),将颜色及其颜色的密度(这个densities感觉可以理解成深浅/透明度)投射到画面上去,就能够生成图像了。
因为体绘制是自然可微的,所以优化我们的表示所需要的唯一输入是一组具有已知相机姿势的图像。我们描述了如何有效地优化神经辐射场,以呈现具有复杂几何和外观的场景的逼真的新视图,并演示了优于先前在神经渲染和视图合成方面的工作的结果。

1 Intro
我们将静态场景表示为一个连续的5D函数,它输出空间中每个点(x, y, z)在每个方向上发射的辐射度(θ, φ),以及每个点上的密度,它就像一个微分不透明度,控制通过(x, y, z)的射线累积的辐射度。我们的方法优化了一个深度全连接神经网络,没有任何卷积层(通常称为多层感知器或MLP),通过从单个5D坐标(x, y, z, θ, φ)回归到单个体积密度和依赖于视图的RGB颜色来表示这个函数。
步骤:1)让摄像机光线穿过场景来生成一个采样的3D点集,2)使用这些点及其对应的2D观看方向作为神经网络的输入来产生一个输出的颜色和密度集,3)使用经典的体绘制技术将这些颜色和密度累积到一个2D图像中。因为这个过程是自然可微的,我们可以使用梯度下降来优化这个模型,通过最小化每个观察到的图像和我们的表示所呈现的相应视图之间的误差。通过将高体积密度和精确的颜色分配到包含真实底层场景内容的位置,最小化跨多个视图的这种误差,鼓励网络预测场景的一致模型。
我们发现,针对复杂场景优化神经辐射场表示的基本实现不会收敛到足够高分辨率的表示,并且在每个摄像机射线所需的样本数量方面效率低下。我们通过使用使 MLP 能够表示更高频率函数的位置编码来转换输入 5D 坐标来解决这些问题,并且我们提出了分层采样程序以减少充分采样此高频场景表示所需的查询数量。
总的来说,就是用MLP表达复杂的几何形状和外观,并非常适合使用投影图像进行梯度下降优化。这种表达方法相比于包分辨率的体素表达来说存储成本更低。
总的来说他们的贡献:
- 一种将由复杂几何结构与材质组成的连续场景,表达为5D神经辐射场,参数化为基本的多层感知机神经网络。
- 发明了一种基于传统体渲染技术(类似于按照图层涂颜色?)。包括一种分层抽样策略,来分配MLP的承载信息容量给可见场景内容的空间(这里之前读的时候没注意到有这部分内容)。
- 将5D坐标映射到更高维空间编码,使MLP能够表达高频场景的内容。(这么做是因为,神经网络趋向于学习低频信息,这应该是一种模型设计的技巧。)
总的来说用一个MLP来表达一个场景很牛逼,但是感觉要是这个场景一变,MLP还得重新训练,虽然有一点有限的应用场景,但在一些问题上面还是有些鸡肋。
2 Related Work
这一章没有关于nerf的直接内容,所以就直接把原文的谷歌翻译贴上了。
计算机视觉最近一个有前途的方向是在 MLP 的权重中编码对象和场景,该权重直接从 3D 空间位置映射到形状的隐式表示,例如该位置的符号距离 [6]。然而,到目前为止,这些方法无法再现具有复杂几何形状的真实场景,其保真度与使用离散表示(如三角形网格或体素网格)表示场景的技术相同。在本节中,我们回顾了这两条工作线并将它们与我们的方法进行对比,我们的方法增强了神经场景表示的能力,以产生用于渲染复杂现实场景的最先进结果。
使用 MLP 从低维坐标映射到颜色的类似方法也已用于表示其他图形功能,例如图像 [44]、纹理材料 [12,31,36,37] 和间接照明值 [38] .
Neural 3D shape representations
最近的工作通过优化将 xyz 坐标映射到有符号距离函数 [15,32] 或占用场 [11,27] 的深度网络,研究了连续 3D 形状作为水平集的隐式表示。然而,这些模型受到访问地面真实 3D 几何的要求的限制,这些几何通常是从 ShapeNet [3] 等合成 3D 形状数据集获得的。随后的工作通过制定可微渲染函数放宽了对地面真实 3D 形状的要求,这些函数允许仅使用 2D 图像优化神经隐式形状表示。 Niemeyer 等人 [29] 将表面表示为 3D 占用场,并使用数值方法找到每条射线的表面交点,然后使用隐式微分计算精确导数。每个光线相交位置都作为神经 3D 纹理场的输入提供,该场预测该点的漫反射颜色。 Sitzmann 等人 [42] 使用不太直接的神经 3D 表示,它简单地在每个连续的 3D 坐标处输出一个特征向量和 RGB 颜色,并提出一个可区分的渲染函数,该函数由一个循环神经网络组成,该网络沿着每条射线行进以决定表面的位置位于。
尽管这些技术可以潜在地表示复杂和高分辨率的几何体,但到目前为止,它们仅限于具有低几何复杂性的简单形状,导致过度平滑的渲染。我们展示了一种优化网络以编码 5D 辐射场(具有 2D 视图相关外观的 3D 体积)的替代策略可以表示更高分辨率的几何形状和外观,以呈现复杂场景的逼真新视图。
View synthesis and image-based rendering
给定密集的视图采样,可以通过简单的光场采样插值技术 [21,5,7] 重建逼真的新视图。对于具有稀疏视图采样的新颖视图合成,计算机视觉和图形社区通过从观察到的图像预测传统几何和外观表示取得了重大进展。一类流行的方法使用基于网格的场景表示,具有漫射 [48] 或视图相关 [2,8,49] 外观。
可微光栅化器 [4,10,23,25] 或路径追踪器 [22,30] 可以直接优化网格表示以使用梯度下降再现一组输入图像。
然而,基于图像重投影的基于梯度的网格优化通常很困难,这可能是因为局部最小值或损失景观条件差。此外,该策略需要在优化前提供具有固定拓扑结构的模板网格作为初始化 [22],这对于不受约束的现实世界场景通常不可用。
另一类方法使用体积表示来解决从一组输入 RGB 图像合成高质量照片级真实感视图的任务。
体积方法能够逼真地表示复杂的形状和材料,非常适合基于梯度的优化,并且往往比基于网格的方法产生更少的视觉干扰伪影。早期的体积方法使用观察到的图像直接为体素网格着色 [19,40,45]。最近,一些方法 [9,13,17,28,33,43,46,52] 使用多个场景的大型数据集来训练深度网络,这些网络从一组输入图像中预测采样体积表示,然后使用alpha 合成 [34] 或学习沿光线合成以在测试时呈现新颖的视图。其他作品针对每个特定场景优化了卷积网络 (CNN) 和采样体素网格的组合,这样 CNN 可以补偿来自低分辨率体素网格的离散化伪影 [41],或者允许预测的体素网格根据输入时间而变化或动画控制 [24]。虽然这些体积技术在新颖的视图合成方面取得了令人印象深刻的结果,但由于它们的离散采样,它们扩展到更高分辨率图像的能力从根本上受到时间和空间复杂性差的限制——渲染更高分辨率的图像需要更精细的 3D 空间采样。我们通过在深度全连接神经网络的参数内编码连续体积来规避这个问题,这不仅比以前的体积方法产生更高质量的渲染,而且只需要那些采样体积表示的存储成本的一小部分.
3 Neural Radiance Field Scene Representation
将一个连续的场景表达为一个5D向量值的函数,输入时3D位置X和2D视角方向$(\theta,\ \phi)$,输出是颜色rgb和体密度$\sigma$。把MLP定义成$F_{\Theta}:(\mathbf{x},\mathbf{d})\rightarrow (\mathbf{c},\mathbf{\sigma})$ 然后优化这个MLP的参数Theta。
其中由于体密度只和位置有关,所以sigma只是x的函数,而颜色rgb则是由x和d同时决定。
网络的实现:
一个8层RELU全连接层,输入是3D位置坐标,输出是体密度sigma以及256维通道的特征,然后把这个处理后的x的特征和视角位置拼接到一起,接入一个额外的全连接层RELU+128通道,输出为rgb颜色。
4 Volume Rendering with Radiance Fields
首先是一个渲染函数,就是辐射场是如何计算得到某个视角下物体颜色的:
$$
C(\mathbf{r})=\int_{t_n}^{t_f}T(t)\ \sigma(\mathbf{r}(t))\ \mathbf{c}(\mathbf{r}(t),\mathbf{d})\ \mathbf{d}t,\ where\ \ T(t)=\exp({-\int_{t_n}^{t}\sigma(\mathbf{r}(s))\mathbf{d}s})
$$
总的来说,颜色C是从tnear位置到tfar位置的每个点散发的颜色的加权叠加。下面解释一下这个渲染方程。
其中T表达的是一个用来表示光能到达t的概率,也就是说,光线从tn到t,一共有多少光能到达t位置,而不是在半路上就和物体的不透明面相遇。由于光路可逆,这也能表示为从t位置有多少光能成功到达tn。
sigma是体密度,也可以理解成是在这个方向上的不透明度,由于只和相机位置有关,所以只是t的函数。
c是在相机特定位置特定角度的颜色。
图形学中很重要的一个问题就是数学公式在实际中如何计算的问题:这里的积分如何计算?
论文中的方法是离散化表达(实际上貌似目前学到的基本都是这么处理的)——将tn到tf这段距离均匀地分成N个箱子,然后计算的时候,在每个箱子里面随机抽取一个样本,作为代表这整个箱子区间的代表。
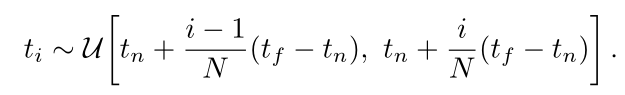
这个公式的意思就是在第i个区间里面抽取一个作为样本。最后实际上的计算公式:
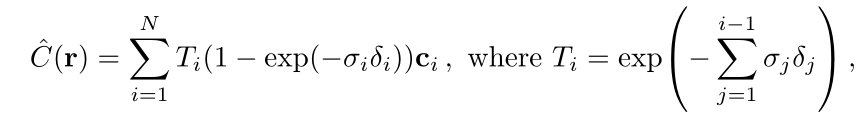
变化的位置:Ti的计算变成离散化的了,这很好理解。sigma的计算在这里其实是采样点的sigma在取样区间内的积分,体密度变成了一个实际的系数值。颜色也因为是取样,所以变成了一个数c。
5 Optimizing a Neural Radiance Field
其实我觉得这一章是nerf最最精彩的一部分,我的理解:作者有了用MLP表示场景的idea,然后尝试建立NERF。但是实际过程中遇到很多问题,效果不理想,这里作者试图优化。
在上一节中,我们描述了将场景建模为神经辐射场并从该表示中渲染新视图所需的核心组件。然而,我们观察到这些组件不足以实现最先进的质量,如第 6.4 节所示)。我们引入了两项改进以实现高分辨率复杂场景的表示。第一个是输入坐标的位置编码,可帮助 MLP 表示高频函数,第二个是分层采样程序,使我们能够有效地对该高频表示进行采样。
想象力和经验都很重要。
5.1 Positional encoding
神经网络确实是一个用来拟合函数的很好用的工具,所以在这里,作者称之为“universal function approximator ”,通用函数的逼近者。这里有个前置知识:深度网络倾向于学习低频函数,在把输入传递给网络之前,用高频函数将输入映射到一个高维空间可以更好拟合包含高频变化的数据。来自reference35。
在这里,作者将之前原有的$F\Theta$重新表示为$F\Theta=F’\Theta\circ \gamma $,也就是说输入经过gamma之后再经过F’。这里面只有F’会学习到参数,gamma是一个固定的函数,用来将输入映射到高维。映射函数:
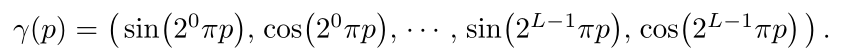
将一个1维实数映射到了2L维向量。这一步做了两件事情:把低维输入转化为了高维输入(这样做有没有用我不知道,不过看上去是把p放到了不同频率的高维向量里面),并且把输入从坐标归一化到正余弦函数的值域中。
这里作者给位置向量的L设为10,给角度方向的向量的L设为4。
这里作者说了其他也用了这种被称作“位置编码”方法的研究:
流行的 Transformer 架构 [47] 中使用了类似的映射,它被称为位置编码。但是,Transformers 将其用于不同的目标,即提供序列中令牌的离散位置作为不包含任何顺序概念的体系结构的输入。相比之下,我们使用这些函数将连续输入坐标映射到更高维空间,使我们的 MLP 能够更容易地逼近更高频率的函数。从投影 [51] 建模 3D 蛋白质结构的相关问题的并行工作也利用了类似的输入坐标映射。
5.2 Hierarchical volume sampling
这部分也是在探讨一个图形学中场景表示的常见问题:对于场景中的一些位置,其实并不重要,但是我却仍为这些位置分配了表达他们的资源。而对于场景中的很重要需要细节的位置,我却因为场景的表示方法,让这些地方的表达所需要的资源和其他平常位置的资源一样。总的来说就是为了解决“好钢被用在刀把上”的问题。
作者之前的方法对摄像机路径上(tn到tf)的N个箱子都设置密集查询,对那些对渲染结果毫无贡献的位置仍然重复采样,这显然不好。于是作者从体积渲染的早期工作中汲取到了灵感,提出了一种层次化表示方法(Hierarchical层次化,不同于之前将提及渲染时候讲的stratified,后者是地层的那种分层,前者是图像金字塔的那种分层),通过根据样本对最终渲染的预期效果按比例分配样本来提高渲染效率。
具体怎么做的:
用两个网络,一个coarse的,用于评估衡量得到分层抽样的权重;一个fine的,根据刚才生成的权重采样,生成最后的结果。
首先采样一系列点作为集合Nc,这些位置上面用方才的分层采样方法。然后算出每个采样点的weight,也就是对于渲染点的贡献。
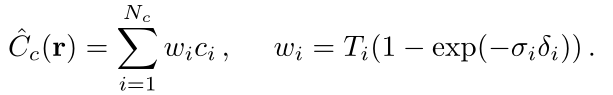
之后将这些权值进行归一化,把W变成W_hat。得到一个光线在路径上的概率密度函数PDF(当然也是个离散的)。
之后我们再根据得到的分布,使用 inverse transform sampling 采样得到另一个点集Nf。最终将点集Nc和Nf合起来,作为最终的点集,重新得到最终的结果。这一步能让我们在可见的位置得到更多的采样结果,实际上实现了对tn到tf的非均匀离散化。
5.3 Implementation details
我们为每个场景优化了一个单独的神经连续体积表示网络。这只需要一个场景的捕获 RGB 图像数据集、相应的相机姿势和内在参数以及场景边界(我们使用地面实况相机姿势、内在和合成数据的边界,并使用 COLMAP 结构从运动包[39] 为真实数据估计这些参数)。在每次优化迭代中,我们从数据集中所有像素的集合中随机抽取一批相机光线,然后按照第 5.2 节中描述的分层抽样从粗网络中查询 Nc 个样本,从精细网络中查询 Nc + Nf 个样本.然后,我们使用第 4 节中描述的体积渲染程序来渲染两组样本中每条光线的颜色。我们的损失只是粗略和精细渲染的渲染像素颜色和真实像素颜色之间的总平方误差。
训练迭代过程大概就是:抽取一系列相机光线,作为一组数据,然后先从粗网络中得到Nc个样本,然后再从精细网络中查询Nc+Nf个样本,然后用体渲染的方法得到光线的最终颜色。
损失函数:只是两个网络分别得到的颜色的均方误差。
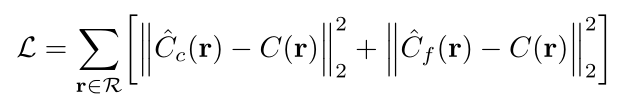
尽管实际上我们最后使用的是Cf的结果,在训练与迭代过程中还是同时优化了Cc。
在我们的实验中,我们使用 4096 条射线的批量大小,每条射线在粗体积中的 Nc = 64 个坐标和精细体积中的 Nf = 128 个附加坐标处采样。我们使用 Adam 优化器 [18],其学习率从 5 × 10−4 开始,并在优化过程中呈指数衰减至 5 × 10−5(其他 Adam 超参数保留默认值 β1 = 0.9,β2 = 0.999,以及 epsilon= 10^−7)。单个场景的优化通常需要大约 100-300k 次迭代才能在单个 NVIDIA V100 GPU 上收敛(大约 1-2 天)。
6 Result
对结果的分析与比对,略去不表
7 Conclusion
我们的工作直接解决了先前使用 MLP 将对象和场景表示为连续函数的工作的不足。我们证明,将场景表示为 5D 神经辐射场(输出体积密度和视图相关的发射辐射作为 3D 位置和 2D 观察方向的函数的 MLP)产生比之前训练深度卷积网络输出的主要方法更好的渲染离散体素表示。
虽然我们已经提出了一种分层采样策略来使渲染更高效(对于训练和测试),但在研究有效优化和渲染神经辐射场的技术方面仍有更多进展。未来工作的另一个方向是可解释性:体素网格和网格等采样表示承认对渲染视图和故障模式的预期质量的推理,但尚不清楚当我们在深度神经网络的权重中对场景进行编码时如何分析这些问题.我们相信这项工作在基于真实世界图像的图形管道方面取得了进展,其中复杂的场景可以由根据实际物体和场景的图像优化的神经辐射场组成。
 wechat
wechat alipay
alipay
